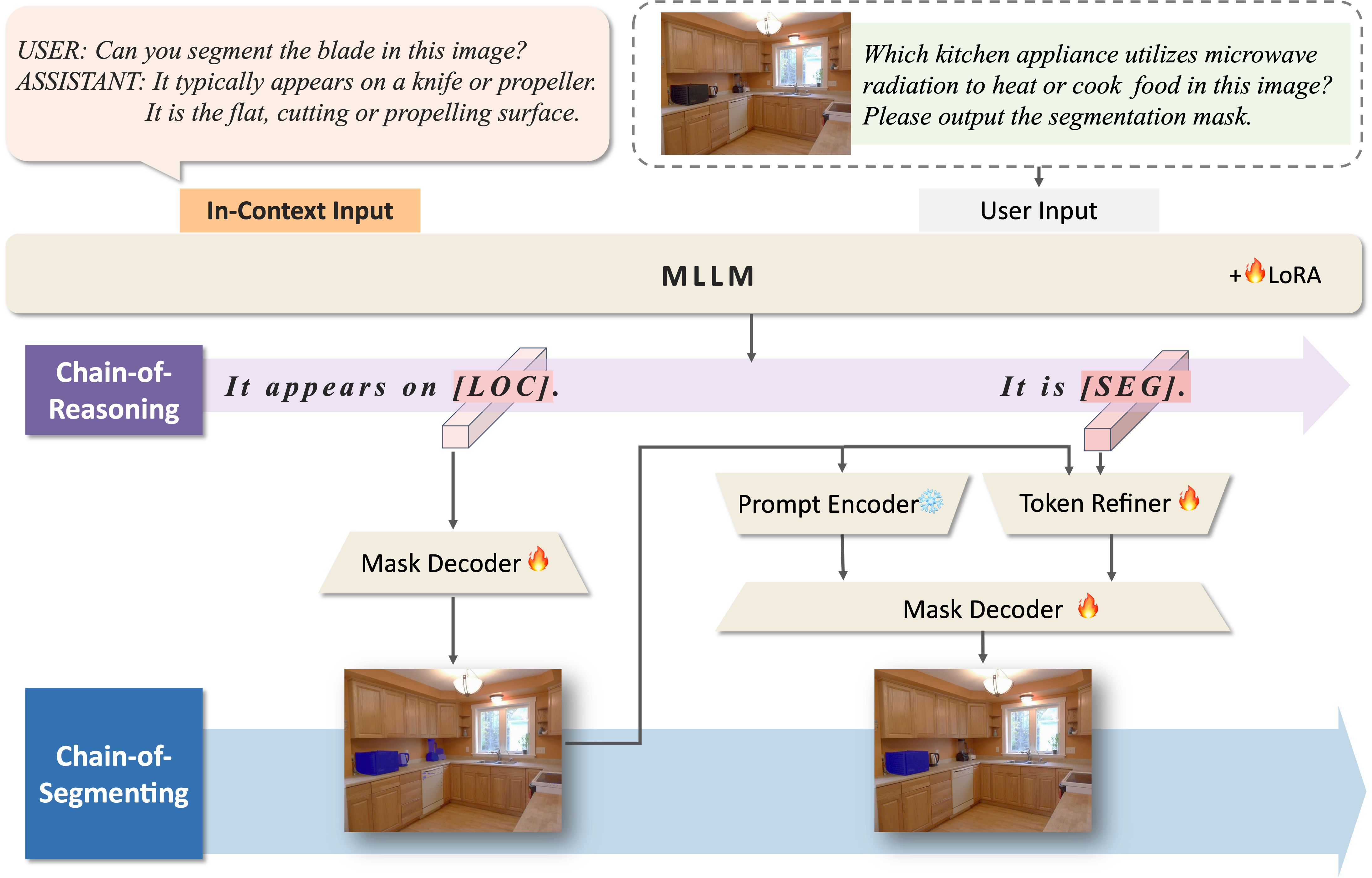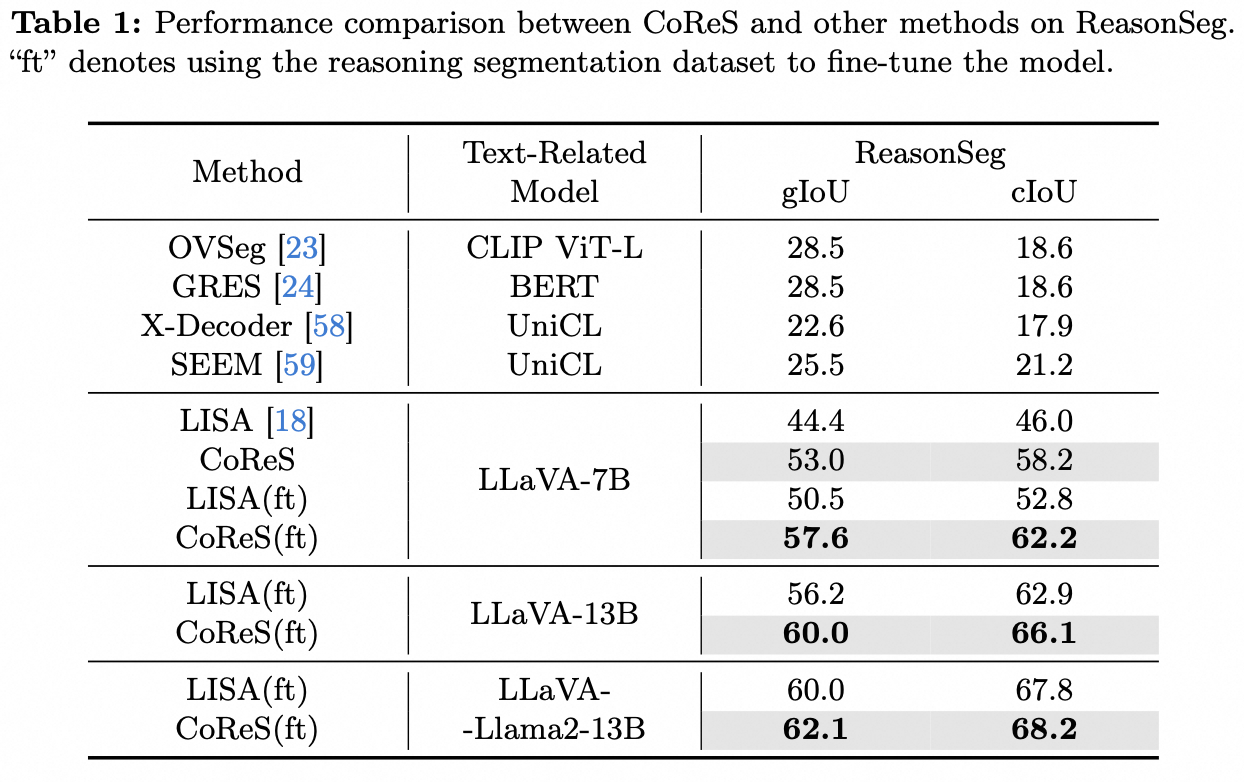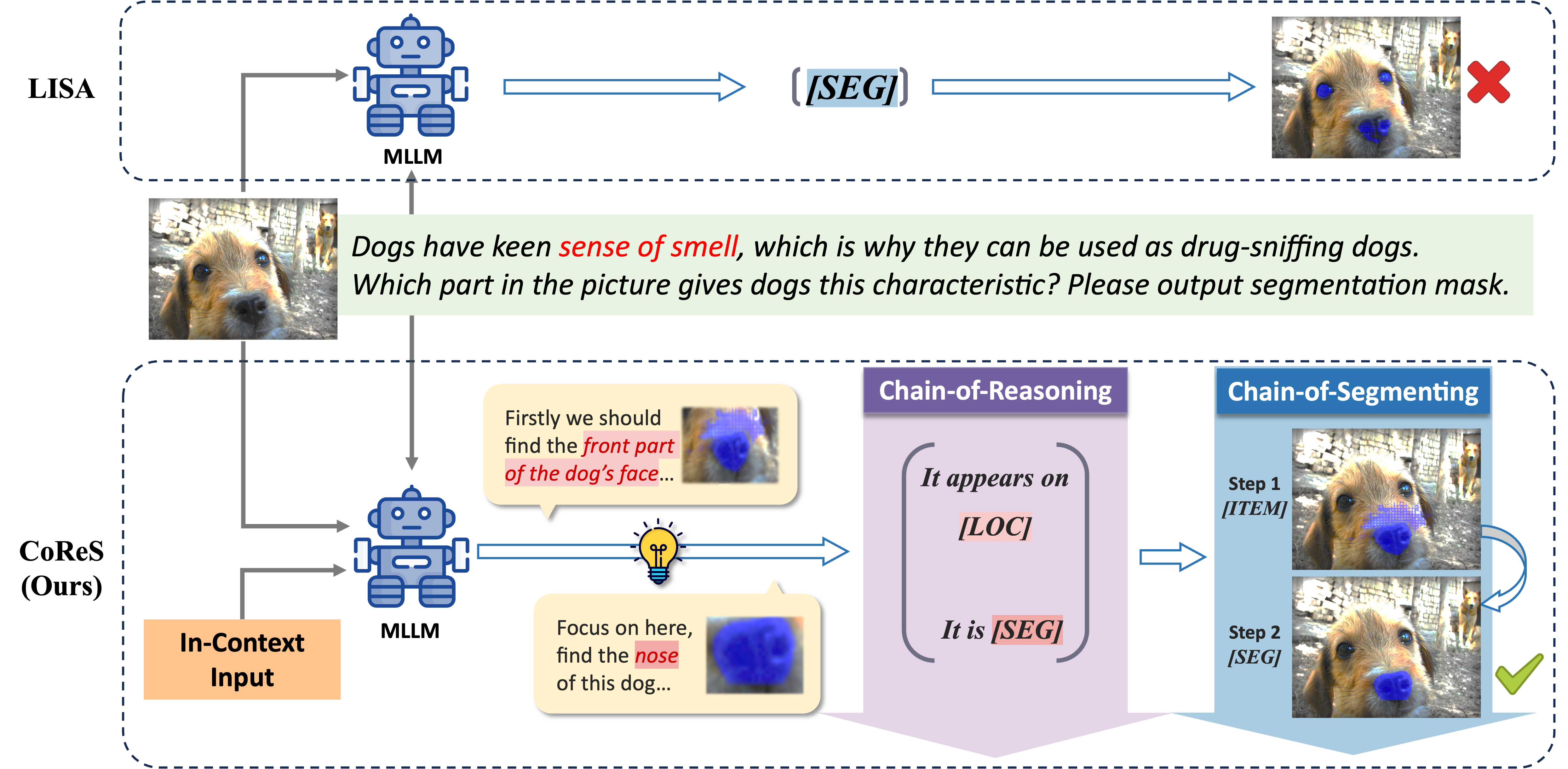
Comparison between our CoReS and LISA. UP: the process of LISA, DOWN: the diagram of CoReS. Given textual and visual inputs, LISA directly uses the [SEG] token output by MLLM to generate a mask. On the contrary, our CoReS involves breaking down the task of "finding the part that gives dogs keen sense of smell" into a logical chain such as "first find the front part of the dog's face, then focus on this specific area, search for the nose of the dog." It can be observed that LISA incorrectly segments the dog's eyes, which are similarly round, dark, and important in sensory perception. In contrast, through in-context input and dual-chain structure, CoReS achieves the segmentation of the nose of the dog correctly.
Visual comparison of CoReS and LISA.